یک ادیسه بصری از بزرگترین رایانه های تاریخ
یک ادیسه بصری از بزرگترین رایانه های تاریخ
توسط Dag Spicer

ده ها سال پیش در آغاز عصر دیجیتال ، دنی هلیس ، پیشگام برنامه نویسی ، در اولین کنفرانس کامپیوتری خود ، در یک هتل هیلتون در شهر نیویورک شرکت کرد. در آنجا ، او تعاملی را مشاهده کرد که از اشتراک گذاری تا به امروز لذت می برد. پس از اینکه یکی از مجریان جسورانه پیش بینی کرد که بازار ریزپردازنده ها روزی میلیونی خواهد بود ، یکی از مخاطبین شکاک صدا کرد: "همه آنها به کجا می روند؟ اینطور نیست که شما در هر دستگیره ای به کامپیوتر احتیاج دارید! "
" سالها بعد ، من به همان هتل برگشتم ، "هیلیس به خاطر می آورد. "من متوجه شدم کلیدهای اتاق با کارت های الکترونیکی جایگزین شده اند که درها را به شکاف در می آورید. در هر دستگیره یک کامپیوتر وجود داشت. "
این افزایش باور نکردنی قدرت محاسبه در هر گوشه و کنار زندگی ما توسط قانون مور هدایت می شد. در سال 1965 ، بنیانگذار اینتل ، گوردون مور ، به طرزی معروض استناد کرد که تعداد ترانزیستورهای یک تراشه تقریباً هر دو سال دو برابر می شود. از آن زمان ، اینتل قانون مور را با نوآوری هایی در طراحی و ساخت ریزپردازنده ثابت کرده است ، که منجر به افزایش مداوم قدرت با کاهش مناسب هزینه می شود.
ما از داگ اسپایسر ، سرپرست ارشد رایانه پرسیدیم. موزه تاریخ ، برای انتخاب 12 ریزپردازنده پیشرفته اینتل از گذشته ما و به اشتراک گذاشتن داستانهای پشت طراحی های متحول کننده رایانه شخصی که آنها طراحی کردند.

1971
ماشین حساب Busicom 141-PF
برای شماره قسمت اینتل: 4004 سرعت ساعت: 108 کیلوهرتز ترانزیستورها: 2،300

 ماشین حساب Busicom 141-PF ، بر اساس ریزپردازنده Intel 4004.
ماشین حساب Busicom 141-PF ، بر اساس ریزپردازنده Intel 4004. در یکی از بزرگترین معاملات در تاریخ تجارت ، اینتل حقوق ریزپردازنده ای را که برای سازنده ماشین حساب ژاپنی Busicom طراحی کرده است ، با 65000 دلار دریافت می کند. این تراشه Intel 4004 بود ، اولین ریزپردازنده تجاری موجود به عنوان یک جزء. اگرچه تقریباً تمام سود اینتل در آن زمان از تراشه های حافظه آن حاصل می شد ، 4004 اولین قدم برای ورود به بازار جدیدی بود - زمانی که سازندگان تراشه های حافظه ژاپنی صنعت تراشه های حافظه ایالات متحده را از بین بردند ، سرانجام مثبت شد.

1972
Micral-N
< p> شماره قسمت اینتل: 8008 سرعت ساعت: 800 کیلوهرتز ترانزیستورها: 3500 میکرو رایانه Micral-N اینتل (1973) ) ، در جمع آوری عوارض بزرگراه در فرانسه استفاده می شود. > img src = "https://cdn-images-1.medium.com/max/426/1*PYXRP-KphkXr4opqioFuSQ.jpeg"> استیو وزنیاک با Micral در سال 1986.
میکرو رایانه Micral-N اینتل (1973) ) ، در جمع آوری عوارض بزرگراه در فرانسه استفاده می شود. > img src = "https://cdn-images-1.medium.com/max/426/1*PYXRP-KphkXr4opqioFuSQ.jpeg"> استیو وزنیاک با Micral در سال 1986. دومین ریزپردازنده اینتل نیز طبق قرارداد برای یک مشتری خارجی ایجاد شد. Computer Terminal Corporation (CTC) اینتل را برای طراحی یک ریزپردازنده تک تراشه برای ترمینال قابل برنامه ریزی Datapoint 2200 خود استخدام کرده بود. در حالی که اینتل تراشه را طراحی کرده بود ، هم Texas Instruments و هم Intel برای ساخت آن قرارداد بستند. مدل Texas Instruments به هیچ وجه کار نکرد و نسخه اینتل دیر شد ، بنابراین CTC به رویکردی پیچیده تر بازگشت. CTC سپس به اینتل اجازه داد تا حق طراحی را به جای ارزش قرارداد اولیه حفظ کند. اینتل که در ابتدا 1201 نامیده می شد ، چند تغییر جزئی در طراحی ایجاد کرد و آن را با نام 8008 عرضه کرد.

1974
MITS Altair 8800
شماره قسمت Intel: 8080 سرعت ساعت: 2 مگاهرتز ترانزیستورها: 4500

 MITS Altair 8800 روی جلد Popular Electronics ، ژانویه 1975.
MITS Altair 8800 روی جلد Popular Electronics ، ژانویه 1975. 8080 اغلب به عنوان اولین ریزپردازنده به اندازه کافی قدرتمند برای ساختن یک کامپیوتر مفید تصور می شود. در حالی که اینتلریزپردازنده های قبلی خانه های طبیعی را در محصولاتی مانند صندوقدار ، کنترل چراغ راهنمایی و ماشین حساب پیدا کردند ، 8080 تراشه ای برای اولین نسل از رایانه های شخصی بود. قابل توجه ترین رایانه مبتنی بر 8080 ، MITS Altair 8800 بود که خبر از انقلاب محاسبات شخصی می داد ، هنگامی که در جلد جلد Popular Electronics در ژانویه 1975 ظاهر شد. MITS مبتنی بر آلبوکرک با سفارشات غرق شد و صدای هیاهو در اطراف Altair باعث ایجاد دو مورد شد. دانشجویان هاروارد ، بیل گیتس و پل آلن ، برای راه اندازی شرکتی-به نام Micro-Soft-برای نوشتن نرم افزار برای آن.
1979
IBM PC
شماره قسمت Intel: 8088 سرعت ساعت: 10 مگاهرتز ترانزیستورها: 29،000
 IBM PC (1981) ، یکی از رایانه های موفق همیشه. نسخه کاهش یافته 8086. با کاهش تعداد اتصالات داده خارجی به 8 (از 16) ، مادربردها ساده تر شدند. همچنین اجازه داد از تراشه های پشتیبانی 8 بیتی استفاده شود که منجر به ارزان شدن رایانه ها شد. مشهورترین طراحی با استفاده از 8088 PC IBM 1981 است که توسط IBM یا توسط سازندگان "کلون" در سراسر جهان ده ها میلیون بازسازی شده است.
IBM PC (1981) ، یکی از رایانه های موفق همیشه. نسخه کاهش یافته 8086. با کاهش تعداد اتصالات داده خارجی به 8 (از 16) ، مادربردها ساده تر شدند. همچنین اجازه داد از تراشه های پشتیبانی 8 بیتی استفاده شود که منجر به ارزان شدن رایانه ها شد. مشهورترین طراحی با استفاده از 8088 PC IBM 1981 است که توسط IBM یا توسط سازندگان "کلون" در سراسر جهان ده ها میلیون بازسازی شده است. 
1982
IBM PC/AT
شماره قسمت Intel: 80286 سرعت ساعت: 6 مگاهرتز ترانزیستورها: 134،000
 IBM PC/AT (1984). < p> 80286 دومین فصل در داستان x86 بود: 3-5 برابر سریعتر از 8088 مورد استفاده در رایانه IBM بود - اما می توانست همه نرم افزارهای مشابه را اجرا کند. از اواسط دهه 1980 تا اوایل دهه 1990 به طور گسترده ای در رایانه ها مورد استفاده قرار گرفت. 80286 همچنین اولین تلاش اینتل برای پشتیبانی از سیستم عامل های چند وظیفه ای بود که در آن شکست یک برنامه کل کامپیوتر را خراب نکرد. برنده اصلی طراحی اینتل PC/AT جدید IBM بود.
IBM PC/AT (1984). < p> 80286 دومین فصل در داستان x86 بود: 3-5 برابر سریعتر از 8088 مورد استفاده در رایانه IBM بود - اما می توانست همه نرم افزارهای مشابه را اجرا کند. از اواسط دهه 1980 تا اوایل دهه 1990 به طور گسترده ای در رایانه ها مورد استفاده قرار گرفت. 80286 همچنین اولین تلاش اینتل برای پشتیبانی از سیستم عامل های چند وظیفه ای بود که در آن شکست یک برنامه کل کامپیوتر را خراب نکرد. برنده اصلی طراحی اینتل PC/AT جدید IBM بود. 1985
Compaq Deskpro
شماره قسمت Intel: Intel386 ™ DX Processor سرعت ساعت: 16 مگاهرتز ترانزیستورها: 275،000
 پردازنده Intel386 DX Compaq Deskpro ، کلون نمادین PC در دهه 1980. انتقال اینتل به معماری 32 بیتی ، گامی مهم که منجر به سریعتر برنامه های کاربردی شد. اولین پردازنده های Intel386 DX فقط به عنوان سرور استفاده می شدند - هیچکس فکر نمی کرد که کاربر دسکتاپ تا به حال به اینقدر قدرت نیاز داشته باشد. وارد مایکروسافت ویندوز شوید که همه این چرخه های فوق العاده اضافی را مصرف می کند. تقریباً یک دهه دیگر طول کشید تا سیستم عامل های 32 بیتی رایج شوند.
پردازنده Intel386 DX Compaq Deskpro ، کلون نمادین PC در دهه 1980. انتقال اینتل به معماری 32 بیتی ، گامی مهم که منجر به سریعتر برنامه های کاربردی شد. اولین پردازنده های Intel386 DX فقط به عنوان سرور استفاده می شدند - هیچکس فکر نمی کرد که کاربر دسکتاپ تا به حال به اینقدر قدرت نیاز داشته باشد. وارد مایکروسافت ویندوز شوید که همه این چرخه های فوق العاده اضافی را مصرف می کند. تقریباً یک دهه دیگر طول کشید تا سیستم عامل های 32 بیتی رایج شوند. 1987
IBM PS/2 Model 25
شماره قسمت Intel: 8086 سرعت ساعت: 5 مگاهرتز ترانزیستورها: 29،000
 IBM PS/2 Model 25 ، بر اساس Intel 8086 .
IBM PS/2 Model 25 ، بر اساس Intel 8086 . ریزپردازنده 8086 اینتل ، سرآغاز خانواده اصلی شرکت "x86" است ، یکی از موفق ترین معماری های رایانه ای در تاریخ و هنوز هم پایه بیش از 90 درصد از تمام رایانه های مورد استفاده امروزی است. در اصل ترکیبی از ویژگی های ریزپردازنده های قبلی 8080 و 8085 ، 8086 از پردازش 16 بیتی پشتیبانی می کند که سرعت و پیچیدگی نرم افزارهای احتمالی را بسیار افزایش می دهد. دو سال بعد ، اینتل تراشه همراه 8087 "پردازنده ریاضی" را معرفی کرد که برنامه های فنی مانند طراحی و گرافیک به کمک کامپیوتر را سرعت بخشید. یکی از اولین رایانه های قابل حمل جهان ، Xerox NoteTaker 1978 ، از 8086 مانند ده ها سیستم دسکتاپ دیگر استفاده کرد.

1989
Gateway 2000 PC
شماره قسمت Intel: Intel486 ™ DX Processor سرعت ساعت: 25 مگاهرتز ترانزیستورها: 1،200،000
1993
HP Netserver LM
مدل اینتل: پردازنده Intel® Pentium® سرعت ساعت: 66 مگاهرتز ترانزیستورها: 3،100،000
 اولین پردازنده های Intel Pentium در سرورهایی مانند این مورد استفاده شد HP Netserver LM (1994).
اولین پردازنده های Intel Pentium در سرورهایی مانند این مورد استفاده شد HP Netserver LM (1994). جانشین Intel486 DX ، پردازنده پنتیوم می توانست دو دستور را به طور همزمان پردازش کند و دارای یک گذرگاه داده 64 بیتی عظیم بود. این در اواسط دهه 1990 به عنوان ریزپردازنده اصلی رایانه های شخصی تبدیل شد. این برنامه می تواند بیش از 100 میلیون دستورالعمل را در ثانیه اجرا کند و برای گرافیک سه بعدی ، بازی ها و ارتباطات صوتی و تصویری از طریق گنجاندن دستورالعمل های ویژه-به نام برنامه های افزودنی چند رسانه ای (MMX) بهینه شده است.
1995
ASCI Red
مدل اینتل: اینتل or پردازنده Pentium® Pro سرعت ساعت: 200 مگاهرتز ترانزیستورها: 5،500،000
 ابررایانه ASCI Red وزارت انرژی ایالات متحده ، ساخته شده با Intel Pentium Pro پردازنده ها.
ابررایانه ASCI Red وزارت انرژی ایالات متحده ، ساخته شده با Intel Pentium Pro پردازنده ها. Pentium Pro اینتل طراحی مجدد "معماری خرد" خانواده x86 بود. این طرح جدید که با نام "P6" شناخته می شود ، مفاهیمی شبیه به ابر رایانه را وارد طراحی ریزپردازنده کرد. Pentium Pro بسیار سریعتر از Pentium بود و دارای یک حافظه ذخیره سازی غول پیکر "cache" بود. همچنین این قابلیت را داشت که حجم کار پردازش را با سایر Pentium Pro ها به اشتراک بگذارد. برای بیشتر رایانه های رومیزی بیش از حد بود اما اغلب در سرورها استفاده می شد. همچنین در ابر رایانه ASCI Red ، اولین رایانه ای که یک تریلیون محاسبه در ثانیه را پردازش کرد ، مورد استفاده قرار گرفت.
2005
Dell Precision 380
مدل اینتل: پردازنده Intel® Pentium® Extreme Edition 840 سرعت ساعت: ترانزیستورهای 3.2 گیگاهرتز: 230 میلیون
 ایستگاه کاری Dell Precision 380 ، بر اساس پردازنده Intel Pentium Extreme Edition 840. < /img>
ایستگاه کاری Dell Precision 380 ، بر اساس پردازنده Intel Pentium Extreme Edition 840. < /img>  نمای داخلی پردازنده Pentium Extreme Edition 840 که دو هسته را نشان می دهد.
نمای داخلی پردازنده Pentium Extreme Edition 840 که دو هسته را نشان می دهد. همانطور که در اواسط دهه 2000 برای سازندگان تراشه مشخص شد که دستیابی به پیشرفت های بیشتر در سرعت ساعت بسیار دشوار است ، تمرکز روی پردازنده های "چند هسته ای" شروع شد. اینها ریزپردازنده هایی بودند که در آنها بیش از یک هسته پردازشی روی یک بسته تراشه ساخته شده بود. Pentium Extreme Edition 840 ، با اسم رمز Smithfield ، در واقع دو هسته پردازنده بود که در کنار هم روی یک قالب ساخته شده بودند. این اولین ریزپردازنده x86 دو هسته ای بود که برای رایانه های رومیزی مانند ایستگاه کاری Dell Precision 380 در نظر گرفته شده بود.
2015
2015 Apple MacBook
مدل Intel: نسل پنجم خانواده پردازنده Intel® Core سرعت ساعت: ترانزیستورهای 1.4 تا 3.1 گیگاهرتز: 1.3 تا 1.9 میلیارد
 اپل 2015 مک بوک از پردازنده های نسل پنجم اینتل Core i5 و i7 استفاده می کند. >
اپل 2015 مک بوک از پردازنده های نسل پنجم اینتل Core i5 و i7 استفاده می کند. > جدیدترین نسل ریزپردازنده های اینتل مطابق با محیط امروزی طراحی شده اند که دارای محاسبات کم مصرف و همراه با پشتیبانی از گرافیک با کارایی بالا و ویژگی های امنیتی داخلی است. به این خانواده تراشه ها با استفاده از لیتوگرافی 14 نانومتری ساخته شده اند:ترانزیستورهایی که استفاده می کند پنج برابر کوچکتر از یک ویروس بیولوژیکی معمولی است. تراشه های این خانواده همچنین از "Hyper Threading" استفاده می کنند که به شما امکان می دهد چندین برنامه را بدون مشکل اجرا کنید.
داگ اسپایسر سرپرست ارشد موزه تاریخ رایانه است ، یک سازمان غیرانتفاعی با سابقه چهار دهه به عنوان نهاد پیشرو در جهان که در زمینه تاریخچه محاسبات و تأثیر مداوم آن بر جامعه کاوش می کند.
توسط Intel پشتیبانی می شود. خیلی چیزها تغییر کرده است ، پشت سر نگذارید! با Intel Inside®
به دنیایی از تجربیات جدید ارتقا دهیدبزرگترین مشکلات حل نشده در علوم کامپیوتر
بزرگترین مشکلات حل نشده در علوم کامپیوتر
برنامه نویسان بسیاری از مشکلات مهندسی چالش برانگیز را به جز این اسرار حل کردند.
 عکس توسط کارلا هرناندز در Unsplash
عکس توسط کارلا هرناندز در Unsplash مبانی نظری علم کامپیوتر برای حل انواع مشکلات چالش برانگیز دنیای واقعی استفاده می شود. هر راه حل فنی دارای اصول اساسی علوم کامپیوتر است. به عنوان مثال ، کنترل نسخه توزیع شده Git…
یادگیری خواندن: روشهای رایانه ای برای استخراج متن از تصاویر
یادگیری خواندن: روشهای رایانه ای برای استخراج متن از تصاویر
نوشته رضا سرشق و کیگان هاینز ، پایتخت یک

مانند بسیاری از شرکتها ، نه م institutionsسسات مالی ، Capital One هزاران سند برای پردازش ، تجزیه و تحلیل و تبدیل به منظور انجام روز دارد -عملیات روز مثالها ممکن است شامل رسیدها ، صورتحسابها ، فرمها ، صورتها ، قراردادها و بسیاری دیگر از دادههای بدون ساختار باشد ، و مهم این است که بتوانید به سرعت اطلاعات جاسازی شده در دادههای غیر ساختار یافته مانند اینها را درک کنید.
خوشبختانه اخیر پیشرفت در بینایی رایانه ای به ما امکان می دهد گام های بلندی در کاهش بار تحلیل و درک اسناد برداریم. در این پست ، ما یک شبکه عصبی پیچشی چند کاره را که به منظور استخراج کارآمد و دقیق متن از تصاویر اسناد توسعه داده ایم ، توضیح می دهیم.
تشخیص نویسه نوری
چالش استخراج متن از تصاویر اسناد به طور سنتی به عنوان تشخیص شخصیت نوری (OCR) شناخته می شود و مورد توجه بسیاری از تحقیقات قرار گرفته است. وقتی اسناد به وضوح تنظیم شده و دارای ساختار جهانی هستند (به عنوان مثال ، نامه تجاری) ، ابزارهای موجود برای OCR می توانند عملکرد خوبی داشته باشند. یکی از ابزارهای باز منبع باز برای OCR ، پروژه Tesseract است که در ابتدا توسط Hewlett-Packard توسعه یافته بود ، اما در سال های اخیر تحت مراقبت و تغذیه گوگل بوده است. Tesseract یک رابط کاربری آسان و همچنین یک کتابخانه مشتری پایتون همراه را ارائه می دهد و به عنوان یک ابزار کاربردی برای پروژه های مرتبط با OCR شناخته می شود. اخیراً ، ارائه دهندگان خدمات ابری قابلیت تشخیص متن را در کنار ارائه های مختلف بینایی رایانه ای خود ارائه می دهند. اینها شامل GoogleVision ، AWS Textract ، Azure OCR و Dropbox و سایر موارد است. این زمان هیجان انگیز در این زمینه است ، زیرا تکنیک های بینایی رایانه به طور گسترده ای برای توانمندسازی بسیاری از موارد استفاده در دسترس قرار می گیرد. راه حل های عمومی کاملاً مناسب نیستند یک مثال ممکن است در تشخیص متن دلخواه از تصاویر صحنه های طبیعی باشد. مشکلاتی از این دست در چالش COCO-Text رسمی شده است ، جایی که هدف استخراج متنی است که ممکن است در علائم جاده ، شماره خانه ، تبلیغات و غیره گنجانده شود. زمینه دیگری که چالش های مشابهی را ایجاد می کند ، استخراج متن از تصاویر اسناد پیچیده است. برخلاف اسناد با طرح کلی (مانند یک نامه ، یک صفحه از یک کتاب ، یک ستون از یک روزنامه) ، بسیاری از انواع اسناد در ساختار خود نسبتاً بدون ساختار هستند و عناصر متنی در سراسر آن پراکنده شده اند (مانند رسیدها ، فرم ها ، و فاکتورها). چنین مشکلاتی اخیراً در چالش ICDAR DeTEXT Text Extraction From Biomedical Literature Figures رسمیت یافته است. این تصاویر با چیدمان های پیچیده ای از بدنه های متنی که در یک سند پراکنده شده اند و توسط اشیاء "حواس پرتی" احاطه شده اند مشخص می شوند. در این تصاویر ، یک چالش اصلی در تقسیم بندی صحیح اشیاء در یک تصویر برای شناسایی بلوک های متن منطقی است. تصاویر نمونه از COCO-Text و ICDAR-DeTEXT در زیر نشان داده شده است. این رژیم های OCR غیر سنتی چالش های منحصر به فردی را شامل می شوند ، از جمله جداسازی زمینه/شی ، مقیاس های متعدد تشخیص شی ، رنگ آمیزی ، جهت گیری متن ، تنوع طول متن ، تنوع فونت ، اشیاء حواس پرتی و انسداد.
 شکل 1. تصاویر نمونه از COCO-Textچالش (چپ) و چالش ICDAR DeTEXT (راست). توجه داشته باشید که OCR در این رژیم مستلزم تشخیص اشیاء متنی جدا از پیکسل های پس زمینه و سایر عوامل مزاحم است.
شکل 1. تصاویر نمونه از COCO-Textچالش (چپ) و چالش ICDAR DeTEXT (راست). توجه داشته باشید که OCR در این رژیم مستلزم تشخیص اشیاء متنی جدا از پیکسل های پس زمینه و سایر عوامل مزاحم است. مشکلات ایجاد شده در OCR غیر سنتی را می توان با پیشرفت های اخیر در بینایی رایانه ، به ویژه در زمینه ، حل کرد. تشخیص شیء همانطور که در زیر بحث می کنیم ، روشهای قدرتمند جامعه تشخیص شیء را می توان به راحتی با مورد خاص OCR تطبیق داد. تصاویر دیجیتالی شده با مقابله با چالش هایی مانند طبقه بندی تصویر ، تشخیص شی ، تقسیم بندی تصویر ، برآورد عمق ، برآورد ژست و موارد دیگر. برای این بحث ، ما بر روی زمینه تشخیص شی (و تقسیم بندی مربوط به تصویر) که در سال های اخیر پیشرفت های چشمگیری داشته است تمرکز می کنیم. تلاش های اولیه برای تشخیص شی بر استفاده از تکنیک های طبقه بندی تصویر در قسمت های مختلف از پیش مشخص شده یک تصویر متمرکز شد. بسیاری از رویکردها بر سرعت بخشیدن به شناسایی مناطق کاندیدا و استفاده از مکانیسم های متحرک برای استخراج و طبقه بندی ویژگی ها متمرکز شده است. در حالی که پیشرفتهای جالبی در این زمینه انجام شده است ، ما در درجه اول بر MaskRCNN تمرکز می کنیم ، مدلی که قادر است با موفقیت تشخیص و تشخیص قطعات تصویر را انجام دهد.
یک نمونه خروجی از MaskRCNN در زیر نشان داده شده است. برای هر تصویر ورودی ، این مدل در تلاش است تا سه چیز را انجام دهد: تشخیص شی (جعبه های سبز) ، طبقه بندی اشیا و تقسیم بندی (مناطق سایه دار رنگارنگ). کادرهای سبز رنگ در تصویر زیر خروجی های مدل هستند و در بالای هر کادر پیش بینی این است که چه نوع شیئی در داخل آن قرار دارد. ما می توانیم مشاهده کنیم که وقتی این صحنه از یک خیابان شلوغ در مدل قرار می گیرد ، MaskRCNN قادر است انواع زیادی از اجسام مختلف صحنه از جمله افراد ، ماشین ها و چراغ های راهنمایی را با موفقیت شناسایی کند. علاوه بر این ، در داخل هر کادر محدود کننده مشخص شده ، منطقه سایه دار رنگی دقیقاً مشخص می کند که پیکسل های یک تصویر مربوط به جسم است. به این تقسیم بندی گفته می شود و هر پیکسل در تصویر یک برچسب طبقه بندی پیش بینی شده دریافت می کند که پیکسل به چه نوع شیئی (یا پس زمینه) تعلق دارد.
MaskRCNN نمونه ای از یک شبکه چند کاره است: با یک ورودی (تصویر) واحد ، مدل باید چندین نوع خروجی را پیش بینی کند. به طور خاص ، MaskRCNN به سه سر تقسیم می شود ، جایی که یکی از سرها با پیشنهاد جعبه های محدود کننده که احتمالاً حاوی اشیاء مورد علاقه هستند ، سر دیگر با طبقه بندی نوع شیء در هر جعبه ، و سر نهایی یک پیکسل را مشخص می کند. bitmask -wise برای برآورد تقسیم بندی در هر جعبه. نکته مهم این است که هر سه سر بر یک نمای مشترک تکیه می کنند که از یک مدل ستون فقرات پیچشی عمیق مانند ResNet یا مشابه محاسبه شده است. این نمایش مشترک در یادگیری چند وظیفه ای مهم است و به هریک از سران اجازه می دهد تا خطاهای مربوط به خود را مجدداً منتشر کرده و این نمای ستون فقرات را به روز کنند. اثر کلی این است که هر سردر واقع دقیق تر از آنچه که به عنوان مدلهای جداگانه آموزش دیده بودند ، می شود. تصاویر. همانطور که احتمالاً حدس می زنید ، ما می توانیم OCR غیر سنتی را به عنوان نزدیک به تشخیص شیء مشاهده کنیم. در این مورد ، ما فقط دو دسته از اشیا داریم که به آنها اهمیت می دهیم: اشیاء متنی و سپس همه چیز دیگر. با این دیدگاه ، ما می توانیم مدلی بسیار شبیه به MaskRCNN را برای شناسایی مناطق مورد علاقه (RoI) در تصویری که احتمال زیاد حاوی متن است ، آموزش دهیم ، وظیفه ای که به عنوان محلی سازی متن شناخته می شود. نمونه خروجی چنین مدلی در زیر نشان داده شده است.
 شکل 3: یک مدل محلی سازی متن روی تصویر رسید تلفن همراه اعمال می شود. بخش های متن جدا از اشیاء صحنه و پیکسل های پس زمینه مشخص می شوند.
شکل 3: یک مدل محلی سازی متن روی تصویر رسید تلفن همراه اعمال می شود. بخش های متن جدا از اشیاء صحنه و پیکسل های پس زمینه مشخص می شوند. توجه داشته باشید که این تصویر ورودی رسید چالش های جالبی برای استخراج متن ارائه می دهد. اول ، سند مورد علاقه در کنار برخی از اشیاء پس زمینه (فرمان) ظاهر می شود. ثانیاً ، متن درون سند بسیار بدون ساختار است و بنابراین شناسایی همه بلوک های متن ممکن به طور جداگانه مفید است. خروجی مدل روی تصویر بالا پوشانده شده است-مناطق متن با کادرهای محدود خط نقطه مشخص شده و ما حتی ماسک پیکسل را برای متن تخمین زده ایم. بالای هر کادر ، کلاس پیش بینی شده و نمره اطمینان وجود دارد ، که از آنجا که ما فقط یک کلاس شی مورد علاقه داریم ، در همه موارد شناسایی شده "Text" است. توجه داشته باشید که جعبه های محدودکننده کاملاً محکم هستند و مناطق متن را به طور دقیق محاسبه می کنند. اصلاح مدلی مانند MaskRCNN و آموزش آن با مجموعه داده های مربوط به OCR منجر به یک رویکرد م effectiveثر برای محلی سازی متن می شود. جالب است بدانید که حتی اگر ماسک پیکسل به طور ذاتی برای OCR مورد نیاز نیست ، ما مشاهده کرده ایم که شامل این محدودیت در یادگیری چند وظیفه ای ، محلی سازی (رگرسیون جعبه محدود) را دقیق تر می کند.
اگر تنها کاری که می توانیم انجام دهیم شناسایی RoI های یک تصویر است که با بلوک های متن مطابقت دارد ، بدیهی است که این ابزار برای OCR محدود است. اما آنچه باید در مرحله بعد انجام دهیم این است که متن موجود در هر ناحیه تصویر را بخوانیم. این به عنوان تشخیص متن شناخته می شود. مدلی که در زیر توضیح داده شده است از MaskRCNN فاصله دارد و یک شبکه چند کاره برای حل بومی سازی متن و تشخیص متن است.
شبکه چند کاره برای استخراج متن
با الهام از مدل ها مانند MaskRCNN ، ما شبکه چند کاره خود را برای حل بومی سازی متن و تشخیص متن طراحی کرده ایم. مشابه روشهای قبلی ، مدل ما شامل یک ستون فقرات متحرک برای استخراج ویژگی های تصویر است. ما هر دو ResNet و Densely Connected Convolutional Networks (DenseNet) را ارزیابی کرده ایم ، که برای آنها متوجه می شویم DenseNet به دقت بالاتری منجر می شود. علاوه بر این ، خروجی پشته حرکتی سپس وارد شبکه هرمی ویژگی می شود که به ترکیب اطلاعات وضوح مکانی بالا از اوایل پشته با جزئیات معنایی با وضوح پایین اما غنی از پشته کمک می کند. اینها اساس ستون فقرات انقلاب را تشکیل می دهندسپس به سر مدل ارسال می شود.
مشابه مدلهای اخیر تشخیص شیء ، سر محلی سازی متن شامل یک مکانیزم دو مرحله ای با یک شبکه پیشنهاد منطقه و سپس یک شبکه رگرسیون جعبه محدود می باشد. خروجی جزء اخیر مجموعه ای از جعبه های پیش بینی شده (RoIs) است که ممکن است حاوی متن باشد. سر دوم مدل ، م componentلفه طبقه بندی است که وظیفه آن تخمین کلاس شیء موجود در هر RoI است - در این مورد ، یک طبقه بندی ساده دوتایی (متن در برابر پس زمینه). سرانجام ، ما سر تشخیص متن را داریم که نقشه های ویژگی را از ستون فقرات متحرک و مختصات RoI ایجاد شده از سر محلی سازی متن را به عنوان ورودی دریافت می کند. این سر تشخیص متن باید ، برای هر RoI ، یک دنباله پیش بینی شده متناسب با متن داخل هر کادر تولید کند و از یک ضرر CTC برای آموزش استفاده کند.
سر تشخیص متن در مقایسه با روش های تشخیص شی ، نقطه اصلی حرکت مدل ما است ، بنابراین برخی موارد اضافی جزئیات ارزشمند است در تشخیص شیء ، نقشه های ویژگی از سطوح متعددی از ستون فقرات متحرک استخراج می شوند و از طریق مکانیزمی که به نام RoIPool (یا RoIAlign) شناخته می شود ، به صورت ثابت جمع می شوند. در OCR ، ما باید اطلاعات وضوح مکانی بالایی داشته باشیم ، بنابراین ویژگی ها را فقط از بلوک های اولیه ستون فقرات پیچشی استخراج می کنیم. علاوه بر این ، ما به یک مکانیسم جمع آوری جدید متکی هستیم که اجازه می دهد اشیاء با نسبت ابعاد مختلف بدون فشرده سازی دنباله های طولانی یا کشیدن دنباله های کوتاه نمایان شوند. سر. یک رویکرد ساده ممکن است برش تصویر ورودی همانطور که توسط RoIs از سر Bound Box Regression مشخص شده و سپس این تصویر بریده شده را از طریق معماری RNN پردازش کند [16]. محدودیت چنین رویکردی این است که ما از نمایش ویژگی های تصویر بین سرها استفاده نمی کنیم ، این امر مستلزم این است که سر تشخیص به تنهایی محاسبات بیشتری انجام دهد. در عوض ، شبکه چند وظیفه ای ما با استفاده از RoI های شناسایی شده و سپس دریافت نمایه های مربوطه برای هر منطقه از ستون فقرات متحرک اقدام می کند. سپس نقشه ویژگی های هر RoI به شکل ثابت تبدیل می شود و توضیحات متن ادامه می یابد.
یک رویکرد معمولی برای طبقه بندی دنباله ها و برچسب گذاری دنباله ها این است که از نوعی RNN استفاده کنیم. به طور متوالی از "چپ به راست" در حدود 200 مرحله فضایی افقی RoI و سعی کنید یک برچسب خروجی برای هر مکان در نقشه ویژگی RoI پیش بینی کنید. با این حال ، ما متوجه می شویم که RNN ها در تشخیص متن در اینجا بسیار ضعیف عمل می کنند. این امر به احتمال زیاد به این دلیل است که ما برای رمزگشایی متن نیازی به در نظر گرفتن همبستگی های طولانی مدت در این دنباله نداریم. در عوض ، ما فقط باید نگاه کنیمچند "ستون ویژگی" در یک زمان به منظور درک اینکه کدام شخصیت در حال نمایش است. به همین دلیل ، ما استفاده از روشهای ساده پیچشی در اینجا با عرض هسته کوتاه برد را بسیار مفید می دانیم. در هر مرحله فضایی ، خروجی پیچیدگی ها برای پیش بینی یک حرف خروجی استفاده می شود و سپس توالی کلی از طریق لایه CTC فرو می ریزد تا دنباله نهایی ROI را نشان دهد.
به منظور آموزش مدل در اینجا توضیح داده شد ، ما به تعداد زیادی تصویر برچسب زده شده نیاز داریم. به جای برچسب گذاری و ایجاد این موارد به صورت دستی ، ما در عوض توسعه اسناد آموزشی مصنوعی خود را انتخاب کردیم. با تنوع کافی در فونت ها ، اندازه ها ، رنگ ها ، اشیاء حواس پرت کننده و غیره ، داده های مصنوعی ما باید به مدلی منجر شود که بتواند بر روی تصاویر دنیای واقعی عملکرد خوبی داشته باشد. ما حدود ده هزار تصویر از این دست ایجاد کردیم که منجر به عملکرد قوی در موارد دنیای واقعی شد که ما در اینجا برجسته می کنیم.
نمونه خروجی های مدل ما در زیر نشان داده شده است. در سمت چپ یکی از تصاویر مربوط به چالش ICDAR DeTEXT و در سمت راست اسکرین شاتی از رسید است. بخش های متن جدا از پیکسل های پس زمینه و سایر اشیاء تصویر مشخص می شوند و با خطوط تیره برجسته می شوند. دنباله متن پیش بینی شده برای هر RoI با رنگ قرمز بالای هر کادر نشان داده شده است. توجه داشته باشید که این مدل می تواند شیء متنی را که با تنوع زیادی نسبت ابعاد ، فونت ها ، اندازه فونت ها و رنگ ها ایجاد می شود ، به طور دقیق تشخیص دهد.
اظهارنظر افشا شده: این نظرات نظرات نویسنده است. مگر اینکه در این پست به طور دیگری ذکر شده باشد ، Capital One به هیچ یک از شرکت های ذکر شده وابسته نیست و مورد تأیید قرار نمی گیرد. همه علائم تجاری و سایر دارایی های معنوی استفاده شده یا نمایش داده شده مالکیت صاحبان مربوطه است. این مقاله © 2019 Capital One است.
این رایانه مغزی از ژوگولار شما مانند کابل USB استفاده می کند
این رایانه مغزی از ژوگولار شما مانند کابل USB استفاده می کند
یک روش جدید برای قرار دادن ایمپلنت های عصبی نیازی به جراحی مغز ندارد
 اعتبار: دانشگاه ملبورن
اعتبار: دانشگاه ملبورن دستگاه هایی که به مردم امکان می دهد مستقیماً مغز خود را به رایانه متصل کنند ، مورد توجه زیادی از سیلیکون ولی قرار گرفته اند. اخیرا. هفته گذشته ، فیس بوک استارتاپ CTRL-Labs را خریداری کرد که در حال توسعه یک مچ بند برای خواندن ذهن است و در ماه ژوئیه ، ایلان ماسک…
اصول طراحی تعامل: برای ایجاد تعاملات مثبت بین انسان و کامپیوتر چه چیزی لازم است
اصول طراحی تعامل: برای ایجاد تعاملات مثبت بین انسان و کامپیوتر چه چیزی لازم است

هر زمان که خود را درگیر یک بازی ویدیویی می کنید ، تعامل خوبی را تجربه می کنید. مثالی دیگر؟ واریز وجه در دستگاه خودپرداز در کمتر از یک دقیقه Ditto - هنگامی که یک برنامه به طور خودکار کد تأیید ارسال شده از طریق پیامک را پر می کند ، هنگامی که به جای باز کردن برنامه از ویجت در صفحه اصلی خود استفاده می کنید و البته هنگام پر کردن صحیح فرم ، علامت سبز را مشاهده می کنید.
متأسفانه ، همه - حتی بهترین ما - تعاملات بدی را تجربه می کنیم. پدر طراحی کاربر محور ، دان نورمن یک کتاب کامل در مورد توصیف طرح های خوب و بد و بیشتر از همه-درهای بد گناهانه نوشت. او در کتاب «طراحی چیزهای روزمره» ابراز تاسف می کند: "مشکلات من با درها به قدری مشهور شده است که درهای گیج کننده اغلب" درهای نورمن "نامیده می شوند. تصور کنید به خاطر درهایی که درست کار نمی کنند مشهور شوید." درهای نورمن درهایی هستند که شما همیشه آنها را هنگام نیاز به کشیدن فشار می دهید و هنگامی که باید آنها را فشار دهید بکشید.
تعاملات بد - در هر دو دنیای فیزیکی و مجازی - موانعی بین کاربر و محصول ایجاد می کند ، مانند یک درب فشار که آنها مرتباً دسته را می کشند. آنها افراد را از رسیدن به هدف خود منصرف می کنند و اغلب آنها را مجبور به تسلیم شدن کامل می کنند. آن زمان است که طراحی تعامل نجات پیدا می کند.
طراحی تعامل (به اختصار IxD) حداقل از دهه 1980 وجود داشته است ، اما اخیراً مانند هر رشته دیگری شکل و شمایل خود را به دست آورده است. و این یک رشته جداگانه است. طراحی تجربه کاربری (UX) رویارویی کلی با استفاده از محصول ، از جمله برنامه نویسی ، معماری اطلاعات ساختمان ، انجام مهندسی قابلیت استفاده و تحقیقات کاربران را شکل می دهد. طراحی تعامل در کمک به کاربر برای رسیدن به هدف خود از طریق تعاملات روان ، لذت بخش و سریع با یک شیء یا ماشین است.
 روابط بین زیر مجموعه های مختلف طراحی UX
روابط بین زیر مجموعه های مختلف طراحی UX اگر یک محصول نرم افزاری یک خانه است و طراحی UX همه چیز است که این خانه را به مکانی دنج و راحت برای زندگی تبدیل می کند ، طراحی تعاملی یک سوئیچ چراغ در نزدیکی ورودی هر اتاق ، یک کف حمام گرم ، یک میز شام به اندازه کافی بزرگ است که می تواند همه اعضای خانواده را در خود جای دهد. در حالی که شما فقط تجربه کلی خود را از زندگی در این خانه به خاطر می آورید ، جزئیات کوچک مانند دیوارهای خوش رنگ و صندلی های راحت این تجربه را تشکیل می دهند.
شما اغلب IxD را با یک اصطلاح دیگر- انسانی- ذکر کرده اید. تعامل رایانه ای (HCI) وقتی اولین رایانه های شخصی به خانه ها و دفاتر افراد حمله کردند ، این ایده که مکالمات بین انسان و ماشین باید شبیه مکالمات انسان و انسان باشد ، محبوبیت پیدا کرد. "تفکر در مورد نحوه بهبود وضعیت برای زیر مجموعه ای کوچک از افراد ، تجربه مثبت را برای بسیاری بهبود بخشید. برای کشف روشهای ایجاد ارتباط بهتر بین ماشینها و انسانها مورد استفاده قرار گرفته است. جان ام کارول ، جان م. کارول ، به عنوان بنیانگذار این زمینه می گوید: "HCI ازتمرکز اولیه آن بر رفتارهای فردی و عمومی کاربران شامل محاسبه اجتماعی و سازمانی ، دسترسی افراد مسن ، افراد دارای اختلال شناختی و جسمی ، و برای همه افراد ، و برای وسیع ترین طیف ممکن از تجربیات و فعالیت های انسانی. "
< h1> قوانین و اصول طراحی تعاملطراحی تعامل در تقاطع بسیاری از روشهای مختلف قرار دارد و بنابراین طراحان هنوز قوانین سخت و سریع این رشته را کشف می کنند. اما ، اصول زیادی وجود دارد که طراحان تعامل در عمل خود به کار می برند که می تواند به عنوان پایه ای برای کل زمینه توصیف شود. بیایید اکنون آنها را بررسی کنیم.
1. قانون فیتس
در سال 1954 معرفی شد و برای محاسبه عملکرد کارگران مونتاژ ، قانون فیتس یکی از اساسی ترین پدیده های تعامل انسان و رایانه را توصیف می کند. این رابطه بین فاصله تا هدف ، سرعت شما و اندازه هدف را نشان می دهد. اساساً می گوید که هرچه شی بزرگتر باشد ، سریعتر می توانید به آن اشاره کنید. با اشاره به مکان نما یا انگشت ، می توانید اندازه یک دکمه را محاسبه کنید تا زمان صرف شده برای آن را کاهش داده و دقت اشاره را افزایش دهید. مدت زمان لازم برای کلیک روی حلقه هایی با اندازه های مختلف که فاصله آنها از یکدیگر متفاوت است.
چگونه می توان آن را در عمل اعمال کرد؟
 کاربر Reddit jbu311 پیشنهاد داد بهبود رابط کاربری که بعداً در وب سایت اجرا شد >
کاربر Reddit jbu311 پیشنهاد داد بهبود رابط کاربری که بعداً در وب سایت اجرا شد > 2. قانون هیک
با نام روانشناس ویلیام ادموند هیک ، قانون هیک حکم می کند که هر چه تعداد انتخاب ها بیشتر باشد ، تصمیم گیری بیشتر طول می کشد. این به یک نتیجه گیری ساده می انجامد: انتخاب زیاد همیشه کار خوبی نیست. با وجود این واقعیت که کاربران به طور غریزی به محصولاتی با ویژگی های بیشتر کشیده می شوند ، راه حل های ساده تر رضایت بیشتری را به ارمغان می آورند.
تصور کنید که وارد یک مغازه ماست منجمد شده و ردیف های بی پایان تاپینگ را مشاهده کنید. شما ساعت ها وقت خود را برای انتخاب بین آنها صرف خواهید کرد. و در حالی که انتخاب دسرها ممکن است سرگرم کننده باشد ، جستجوی لیستی از ژانرهای کتاب در یک فروشگاه آنلاین اینطور نیست. به هر حال ، آمازون با سخاوتمندی قانون Hick را برای طبقه بندی انتخاب گسترده لیست ها اعمال می کند. برای یافتن بخش مورد نیاز ، باید همه آنها را بخوانید ، اما این کار را در مقادیر اندازه گیری شده ، با گام به گام در بخش های مختلف انجام دهید.
 قانون هیک در مورد آمازون
قانون هیک در مورد آمازون چگونه می توان آن را در عمل اعمال کرد؟
3. قانون تسلر
در اواسط دهه 1980 ، دانشمند کامپیوتر اپل و سپس معاون رئیس اپل لری تسلر مدلی را ارائه کرد که می گوید: "هر برنامه کاربردی باید دارای مقدار ذاتی پیچیدگی غیر قابل کاهش باشد. تنها س isال این است که چه کسی باید با آن برخورد کند. " این قانون اساساً پایه و اساس روند امروز به سمت رابط های مینیمالیستی است ، که در آن کاربران از آن استفاده نمی کنندتسلر در مصاحبه ای با کتاب طراحی برای تعامل بیل موگرج می گوید: "تا زمانی که طراحی به اندازه کافی ساده نباشد ، طراح ارشد دست از کار نخواهد کشید." حتی اگر روزها یا هفته های بیشتری طول بکشد ، باید آشفتگی را از رابط کاربری حذف کرده و در مرحله پشت سر هم با آن کنار بیایید.
چگونه می توان آن را در عمل اعمال کرد؟
4. پنج زبان (ابعاد) طراحی تعامل
در طراحی برای تعامل ، گیلیان کرامپتون اسمیت دانشگاهی با قابلیت استفاده مفهومی از چهار بعد (یا زبان) طراحی تعاملی ارائه داد. به گفته کرامپتون اسمیت ، این زبانها اصل همه تعاملاتی هستند که به انسانها و ماشینها در برقراری ارتباط موثر کمک می کنند. بعدها ، طراح کوین سیلور بعد پنجم را پیشنهاد کرد و بدین ترتیب مفهومی را که امروزه به عنوان 5 بعد طراحی تعامل شناخته می شود ، ایجاد کرد. طراحان از آنها برای تجزیه و تحلیل فعل و انفعالات فعلی و پرسیدن س questionsالات در هر بعد استفاده می کنند.
1D: کلمات. این زبانی است که ما برای توصیف فعل و انفعالات و معنای پشت هر دکمه ، برچسب یا دال استفاده می کنیم. کلمات باید برای کاربران نهایی واضح و آشنا باشند و به طور مداوم و مناسب با تنظیمات مورد استفاده قرار گیرند.
 SoundCloud از واژه های م effectiveثر برای توصیف دامنه عملکرد سرویس استفاده می کند
SoundCloud از واژه های م effectiveثر برای توصیف دامنه عملکرد سرویس استفاده می کند 2D: نمایش های بصری. اینها همه تایپوگرافی ، تصاویر ، نمادها و یک پالت رنگی است که کاربران به طور غیر ارادی درک می کنند.
 سبک بصری تمیز اما متمایز رسانه ، لحن اشتراک گذاری و درک محتوای متنی را تعیین می کند >
سبک بصری تمیز اما متمایز رسانه ، لحن اشتراک گذاری و درک محتوای متنی را تعیین می کند > 3D: اشیاء فیزیکی یا فضا. این شامل صفحه کلیدهای کامپیوتر ، موش ها ، صفحه های لمسی و صفحه های لمسی است که کاربران با آنها ارتباط برقرار می کنند و فضایی که در آن تعامل دارند.
 استفاده از Evernote در Apple Watch
استفاده از Evernote در Apple Watch 4D: زمان. حرکات ، صداها ، انیمیشن ها-همه عناصر تعاملی که با گذشت زمان تغییر می کنند-به کاربر درک درستی از پیشرفت اقدامات خود و انجام بازخورد در مورد آن را می دهد.

انیمیشن ها در طراحی مواد Google
5D: رفتار. نحوه واکنش کاربران نسبت به تعامل ، پاسخ جسمی یا احساسی آنها ، چه احساس رضایت داشته باشند و چه برای ادامه روند روی دکمه بعدی کلیک کنند.
6. هفت مرحله عمل نورمن
استاد نور Don Don Norman نه تنها به دلیل نفرت از درهای گیج کننده مشهور است. او همچنین 7 مرحله از یک عمل را شرح داده است که هر فرد در زندگی روزمره خود از آن عبور می کند. این مراحل در سه سطح انجام می شود: اهداف ، اجرا و ارزیابی. بیایید آنها را با استفاده از یک مثال ساده تجزیه کنیم.
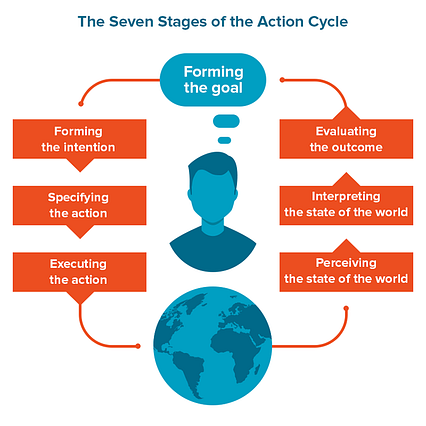 هفت مرحله از چرخه عمل
هفت مرحله از چرخه عمل مرحله 1. تعیین اهداف - من می خواهم چه کار کنم؟
رزرو اتاق هتل.
مرحله 2. شکل گیری نیت - آنچه باید انجام شود آیا من برای برآوردن این هدف تلاش می کنم؟
در یک وب سایت رزرو ، اتاق هتلی را که دوست دارم پیدا کنم.
مرحله 3. تعیین توالی عملکرد - دقیقاً چگونه به این هدف می رسم؟
مرورگر را باز کنید. وارد Booking.com شوید. پارامترهای من (مکان ، تاریخ ، تعداد مهمانان ، فیلترهای دیگر) را مشخص کنید. نتایج جستجو را پیمایش کنید. نتایج مورد علاقه من را در یک برگه جدید باز کنید تا بعداً ذخیره شوند. نتایج انتخاب شده را مقایسه کرده و بهترین گزینه را بیابید. روی کتاب و غیره کلیک کنید. مرحله جهان - از حواس خود برای ارزیابی احساسات خود در حال حاضر استفاده کنید.
آیا من مراحل رزرو را به پایان رساندم؟
مرحله 6. تفسیر ادراک - بفهمید آیا چیزی تغییر کرده است .
آیا من یک ایمیل تأیید در صندوق ورودی دارم؟
مرحله 7. مقایسه نتیجه با هدف - آیا من به هدفم رسیدم؟
بله.
به گفته نورمن ، افراد هنگام استفاده از یک محصول با دو خلیج روبرو می شوند: خلیج اعدام و خلیج ارزیابی. خلیج اعدام لحظه ای است که مردم سعی می کنند نحوه استفاده از آن را بیابند. خلیج ارزشیابی زمانی است که آنها می آموزند چه چیزی تغییر کرده است و آیا اقدام آنها را به هدف رسانده است. نورمن خاطرنشان می کند که در بسیاری از موارد ، وقتی مردم با مشکلاتی روبرو می شوند ، خود را سرزنش می کنند و تسلیم می شوند و تصمیم می گیرند که خیلی احمق هستند.درک روانشناسی اقدامات انسانی به ما کمک می کند تا تعاملاتی ایجاد کنیم که هر دو خلیج را پل بزند.
7. عدد جادویی هفت
اصل دیگری که از عدد هفت استفاده می کند توسط روانشناس جورج میلر ابداع شد. در سال 1956 ، وی مقاله ای به نام شماره جادویی هفت ، به علاوه یا منهای دو نوشت: برخی از محدودیت ها در توانایی ما در پردازش اطلاعات که استدلال می کند تعداد متوسط اقلامی که یک انسان می تواند در حافظه کاری خود نگه دارد 7 ± 2 است. حافظه فعال بخشی از حافظه کوتاه مدت است که مسئول درک و پردازش فوری است. این بدان معناست که در یک عکس ، یک انسان می تواند 5 تا 9 مورد را به یاد آورد ، یعنی مواردی با همان ویژگی. شماره تلفن یا تأمین اجتماعی رایج ترین نمونه هایی از رشته هایی هستند که خود را به قطعات می رسانند.
 Google همه اطلاعات را به صورت تکه های کوچک قابل درک نشان می دهد
Google همه اطلاعات را به صورت تکه های کوچک قابل درک نشان می دهد چگونه می توان آن را در عمل اعمال کرد؟
آینده طراحی تعامل
در سال 1965 ، بنیانگذار اینتل گوردون مور پیش بینی کرد که قدرت محاسبه دستگاه ها هر دو سال دو برابر سریعتر می شود. این امر برای چندین دهه ثابت شده است و تنها در ارزیابی های اخیر به این نتیجه رسیدند که این دوره در حال حاضر 18 ماه طول می کشد ، نه 24 ، اما به ارتفاع عملکرد رسیده است. عجیب است که توجه کنیم پیشرفت های الکترونیکی چقدر بر نحوه طراحی ما تأثیر گذاشته است.
فن آوری های صوتی ، AR و VR و دستگاه های اینترنت اشیاء نحوه تعامل کاربران با دنیای مجازی را تغییر می دهند اما تغییر زیادی در نحوه طراحی این تعاملات ایجاد نمی کند. سادگی ، کاهش اشتباهات ، قابل دسترس تر و قابل پیش بینی بودن رابط ها ایده هایی است که طراحان گذشته و حال با آن اشتراک دارند. این بدان معنا نیست که چیز دیگری برای یادگیری وجود ندارد. دانشمندان رایانه و علوم شناختی همچنان تلاش می کنند تا راههای بهتری برای کمک به انسانها و کمک به طراحان برای درک آنها پیدا کنند.
چه اصول طراحی تعاملی را در طراحی خود به کار می برید؟ و به نظر شما کدامیک را باید در مقاله به روز شده بررسی کنیم؟ نظرات و پیشنهادات خود را در زیر بیان کنید.
داستان را دوست دارید؟ با کف زدن به ما اطلاع دهید تا افراد بیشتری بتوانند آن را پیدا کنند!